Join my stream Thursday 6/4/26 with guests from OpenChoreo, a new CNCF Kubernetes "AI abstraction" with built-in agents and all the fixin’s for managing K8s with agents.

KubeCon has been talking about AI in every keynote since the launch of ChatGPT, but it wasn't what you think. Before that moment in consumer AI, the language of AI was MLOps-specific and rarely highlighted at KubeCon. Soon after the chatbots launched, keynotes started telling me that Kubernetes was awesome for training models, and that “running inference” was the new Kubernetes problem, and that I’d be soon managing GPUs and huge models running in my clusters. Except, I really didn’t care about that. (Turns out many others didn’t either.) I wanted to use AI in my job, not run it for others.
This post is about the job of running Kubernetes in an AI-enabled world, and where K8s might be headed to become an Agent-first platform.
It’s not about training models, reinforcement learning, or hosting inference on Kubernetes. I call that AIOps or MLOps. You might say that’s the role of an “AI Engineer”. That's not me.
What I do want to talk about is AI-native or AI-enabled engineers who use LLMs to do their jobs. Primarily using local AI-assistants (agent harnesses like Claude Code) or remote agents to automate toil that previously required human judgment, correlation, or summarization, like agents inside CI workflows or SRE troubleshooting bots.
I’ve been calling this role Agentic DevOps for over a year, then started the podcast dedicated to it, and I might have been a little early in casually using the term to describe a new role in our existing jobs, but it’s finally catching on. (Note: I use DevOps in the name, but I also include platform and site reliability engineers. Anyone in the job of building or maintaining infrastructure is included; I just needed to pick a catchy keyword, and Agentic Ops sounded too much like AIOps.)
In 2024, engineers were still telling me, even at KubeCon, that genAI didn’t have a role in infrastructure management, and they were, at most, using it to write YAML and TOML. At the time, we couldn't trust the token output.
We infra and ops people live in a world of continually pursuing determinism, and before late 2025, LLMs were the opposite of that.
In 2025, a small few pointed Claude Code at their infra APIs (AWS, GCP, K8s) and began to test what was possible. I even heard of people installing CC on their host servers to perform admin and troubleshooting tasks (I do not recommend that!).
Finally, in 2026, I’m seeing the signs everywhere that infra operators are plugged into the vision and getting on board the ADO train (If I’m gonna make Agentic DevOps stick in enterprise, it’s gotta have an acronym amiright?). The SOTA models, with the right context, are now good enough. Our primitives are becoming widely understood: Agent markdown files, Skills, Evals, and MCP’s. I’m sure more abstractions will come eventually, but we’ve got enough to get started.
All that’s left is to understand the best patterns and practices for how to implement these new primitives without breaking production or accidentally burning a pile of token money.
Three types of Kubernetes + AI engineering roles
One of the problems is that everything is labeled AI, Agent, or Agentic. Those terms have lost all meaning on their own. In my new Agent Harness Setup for DevOps course, I have to start by defining terms to avoid generic usage like “Agent” and call it something specific: Agent Harness, or Server Agent, or Subagent, etc. This terminology overloading problem extends to Kubernetes itself, where there are three major areas where K8s and AI meet.
Here are my definitions of AI-in-Kubernetes job roles, in the order these roles appeared in the ecosystem:
- Type 1: Kubernetes as a host for model training, reinforcement learning, and inference (MLOps/AIOps). I still think most of us will not need to know this, despite the insistence by KubeCon keynotes. I see it as a specialty where data science and GPU ops meet. I talk to lots of DevOps/SRE/PE people and only a few of them deal with this as a new job role. Am I wrong? What are you seeing? Let me know by replying to this email, or replying on BlueSky, X, LinkedIn, or Substack.
- Type 2: Running line-of-business AI-enabled workloads, usually built with an Agent SDK and behaving like a normal pod. Think of adding AI chatbots to a line-of-business app. Most of us will treat this as normal technology and might not even know we’re deploying it for our internal business teams. Someone else will run the inference we're using in these apps. It’s just a pod. Doing this doesn’t mean you need #1. Nothing to see here, move along.
- Type 3: Agentic Operations: Using AI coding assistants (Claude Code, Codex, Copilot), agent SDKs + agent platforms (kagent, Claude Code Cloud, Cursor Automations, GitHub Agentic Workflows, Warp Oz), and agent harness orchestrators (OpenClaw, Hermes, NanoClaw, PicoClaw, ZeroClaw) to run 24/7 somewhere with limited access to help you troubleshoot, correlate ops data, or create PRs. This is where I live now.
Agentic Operations is the new hotness; many just don’t know it yet
Server Agents are a new kind of infrastructure that you’ll be spending an increasing amount of your time on, if you aren’t already. Members of my Agentic DevOps Guild spend time every week learning and thinking about how they can move the needle on team productivity by adopting more of the projects listed in my maturity model (a work in progress based on months of interviewing dozens of teams).
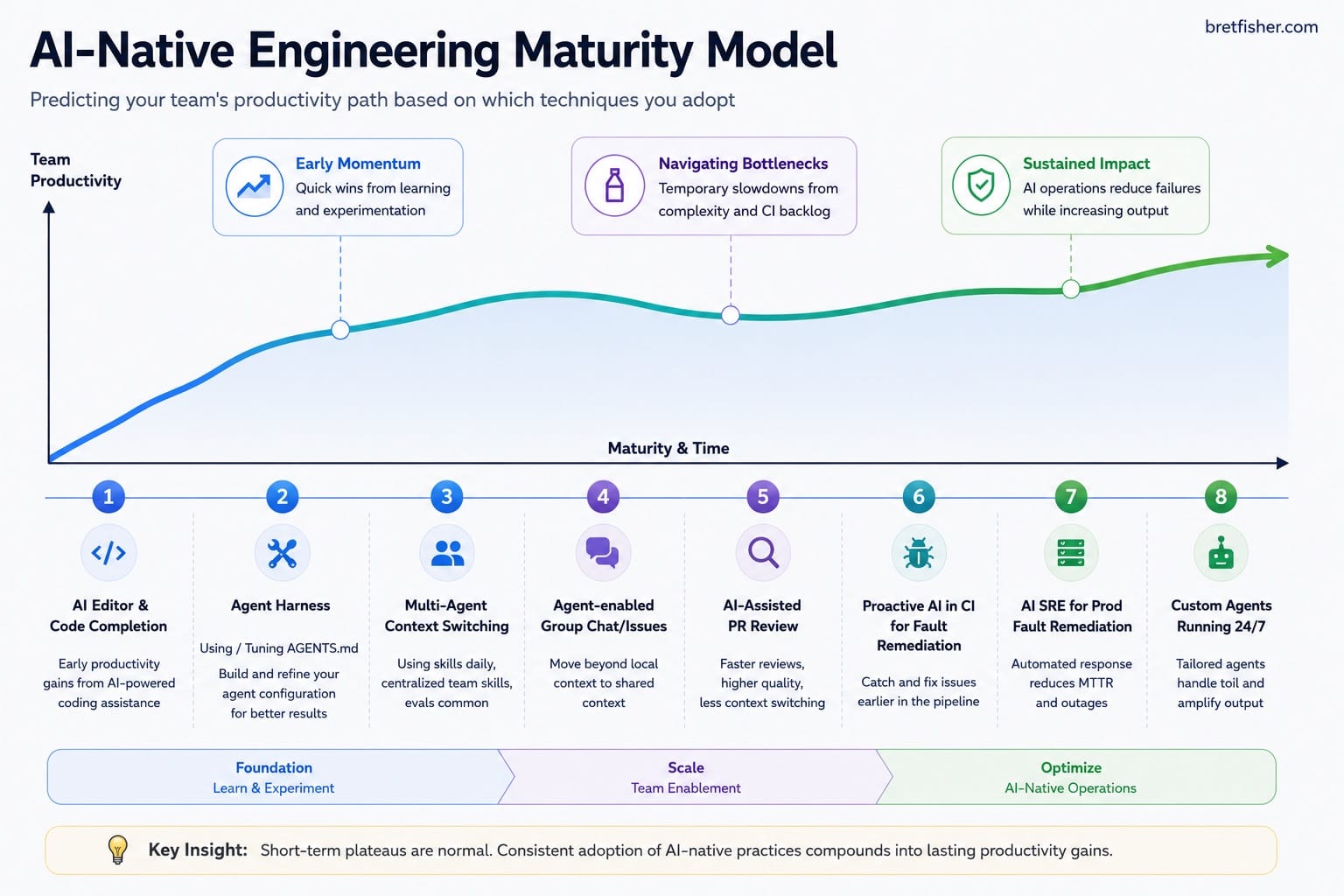
(In future posts, I'll detail what I'm seeing in each of those areas of focus.)
Kubernetes, CI, and cloud APIs are the epicenter of what our agents will manage
Every team's path is different, but it tends to start with learning local agent harnesses, then applying that learning to CI and existing automation workflows, and eventually creating new infrastructure to run and manage an increasing set of agents that help humans go faster throughout the software lifecycle. You might call this the Agentic Development Life Cycle (ADLC), which mirrors the SDLC. Agents aren't magical new things; they are just more of the same in the ops world: software tools we'll run that help engineers manage more resources and go faster. This is what we've been doing for many decades, with each wave of new tech giving sysadmins the ability to manage more systems and more software.
Just as it's normal to run our systems in virtual machines, which were unheard of 25 years ago, this wave of innovation will make it normal to have agents inside your infrastructure and in every architectural design.
So what does that mean for Kubernetes in an agentic world?
Well, I'll make some predictions here, but it's mostly just more of what we're already doing:
- Bigger and more clusters. Agents will help us scale and deal with complexity. Just like app dev teams are looking less at the code they're shipping, we'll probably look less at the YAML/TOML/JSON that agents are creating. This has pros and cons but that doesn't mean it won't happen. This is a form of Jevons paradox, so as the human is able to manage more infrastructure (because agents become a new abstraction on top of everything) then we'll be making more of it.
- Policy as a first-class requirement, earlier in the pipeline. The faster and more complex we try to go, the more guardrails we need. Agents need to have the policies in their context when modifying infrastructure, not as a fail-safe in a kubectl apply. Kyverno and other policy engines are already thinking about how to shift-left. Prempti is a new project that ensures agent tool calls adhere to Falco policies.
- Generic-ish agents are built into every K8S distribution. For the foreseeable future, we will likely continue to build custom agents to align with our team goals and business objectives. Yet, much of our infrastructure complexity is just boilerplate resources. We'll need a CNCF project that's a model-agnostic custodian that becomes our first way to interact with clusters, and just works out of the box. It'll be secure by default, have auto-updated context about its environment all the way down, and "just work" on day one of a cluster. Maybe it'll be a set of agents, each offloading work to the others. Maybe it'll need an MCP layer, or it just manages APIs directly. Maybe it'll be A2A-enabled, so our local harness reaches out to it. The bottom line is that we will rarely use kubectl ourselves.
- Recovery will be even more important. Better rollbacks, more versioning, snapshots, agents that auto-test backups, chaos monkeys, etc. Agents will help smaller teams operate safely in a way that was off-limits to most without the budgets of big tech (if we can afford the tokens 😏)
- More identity management. We'll need built-in features that let us grant permissions dynamically, track them centrally, expire them quickly, and learn what it means to have an auth/IAM model for agents. Having one agent with root access to everything "just in case it needs it" won't work, nor will "give it read-only as we don't trust it." The agent permissions can't be fixed at deployment time.
- An agent graph is part of our observability. The faster things happen, the more we'll need to know what agents are running where, what they have access to, who they can talk to, and what they did.
This is just a small list, but I think it's a good start for looking ahead a few years. There's so much new stuff to think about, it can be exhausting, I know. The great thing is we don't have to boil the ocean. No one's saying (yet) Kubernetes will need replacing with new cloud primatives because of AI. Our existing skills are still valuable, and agents will help us with the areas we are weak in, and let us do things we never had the time to learn before. I'm here for it, let's go!



